# A tibble: 168 × 6
restaurant price food decor service geo
<chr> <dbl> <dbl> <dbl> <dbl> <chr>
1 Daniella Ristorante 43 22 18 20 west
2 Tello's Ristorante 32 20 19 19 west
3 Biricchino 34 21 13 18 west
4 Bottino 41 20 20 17 west
5 Da Umberto 54 24 19 21 west
6 Le Madri 52 22 22 21 west
7 Le Zie 34 22 16 21 west
8 Pasticcio 34 20 18 21 east
9 Belluno 39 22 19 22 east
10 Cinque Terre 44 21 17 19 east
# ℹ 158 more rowsMultiple Linear Regression
Summarizing linear relationships in high dimensions
In the last lecture we built our first linear model: an equation of a line drawn through the scatter plot.
\[ \hat{y} = 96.2 + -0.89 x \]
While the idea is simple enough, there is a sea of terminology that floats around this method. A linear model is any model that explains the \(y\), often called the response variable or dependent variable, as a linear function of the \(x\), often called the explanatory variable or independent variable. There are many different methods that can be used to decide which line to draw through a scatter plot. The most commonly-used approach is called the method of least squares, a method we’ll look at closely when we turn to prediction. If we think more generally, a linear model fit by least squares is one example of a regression model, which refers to any model (linear or non-linear) used to explain a numerical response variable.
The reason for all of this jargon isn’t purely to infuriate students of statistics. Linear models are one of the most widely used statistical tools; you can find them in use in diverse fields like biology, business, and political science. Each field tends to adapt the tool and the language around them to their specific needs.
A reality of practicing statistics in these fields, however, is that most data sets are more complex than the example that we saw in the last notes, where there were only two variables. Most phenomena have many different variables that relate to one another in complex ways. We need a more powerful tool to help guide us into these higher dimensions. A good starting point is to expand simple linear regression to include more than one explanatory variable!
Multiple Linear Regression
- Multiple Linear Regression
- A method of explaining a continuous numerical \(y\) variable in terms of a linear function of \(p\) explanatory terms, \(x_i\). \[ \hat{y} = b_0 + b_1x_1 + b_2x_2 + \ldots +b_px_p \] Each of the \(b_i\) are called coefficients.
To fit a multiple linear regression model using least squares in R, you can use the lm() function, with each additional explanatory variable separated by a +.
Multiple linear regression is powerful because it has no limit to the number of variables that we can include in the model. While Hans Rosling was able to fit 5 variables into a single graphic, what if we had 10 variables? Multiple linear regression allows us to understand high dimensional linear relationships beyond what’s possible using our visual system.
In today’s notes, we’ll discuss two specific examples where a multiple linear regression model might be applicable
A scenario involving two numerical variables and one categorical variable
A scenario involving three numerical variables.
Two numerical, one categorical
The Zagat Guide was for many years the authoritative source of restaurant reviews. Their approach was very different from Yelp!. Zagat’s review of a restaurant was compiled by a professional restaurant reviewer who would visit a restaurant and rate it on a 30 point scale across three categories: food, decor, and service. They would also note the average price of a meal and write up a narrative review.
Here’s an example of a review from an Italian restaurant called Marea in New York City.
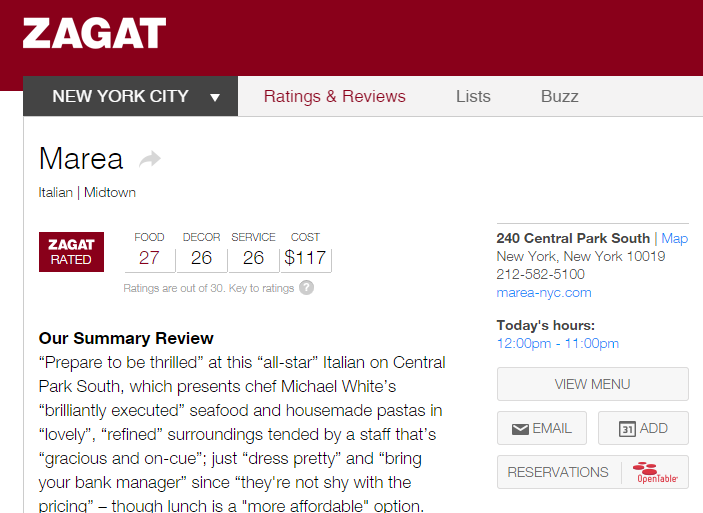
In addition to learning about the food scores (27), and getting some helpful tips (“bring your bank manager”), we see they’ve also recorded a few more variables on this restaurant: the phone number and website, their opening hours, and the neighborhood (Midtown).
You might ask:
What is the relationship between the food quality and the price of a meal at an Italian restaurant? Are these two variables positively correlated or is the best Italian meal in New York a simple and inexpensive slice of pizza?
To answer these questions, we need more data. The data frame below contains Zagat reviews from 168 Italian restaurants in Manhattan.
Applying the taxonomy of data, we see that for each restaurant we have recorded the price of an average meal, the food, decor, and service scores (all numerical variables) as well as a note regarding geography (a categorical nominal variable). geo captures whether the restaurant is located on the east side or the west side of Manhattan1.
Let’s summarize the relationship between food quality, price, and one categorical variable - geography - using a colored scatter plot.
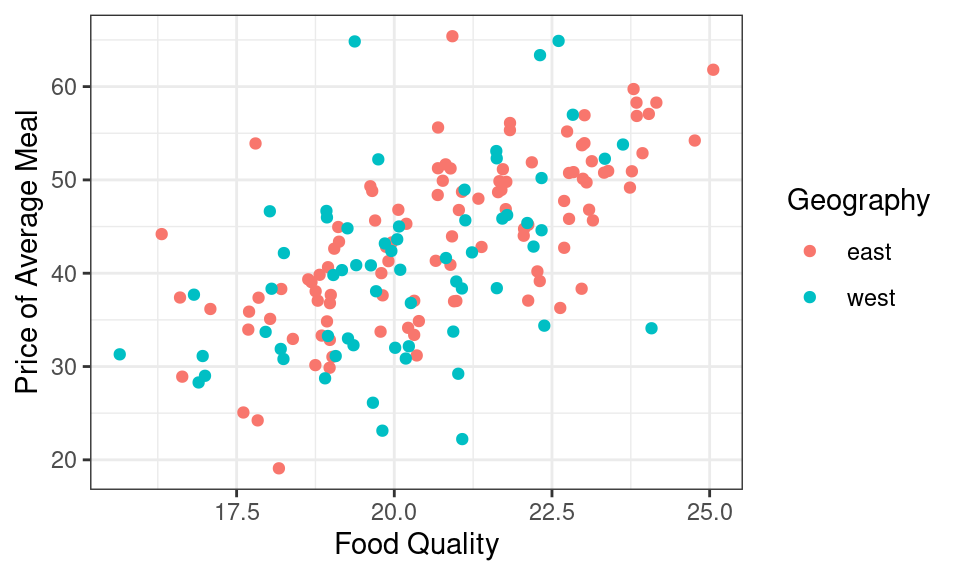
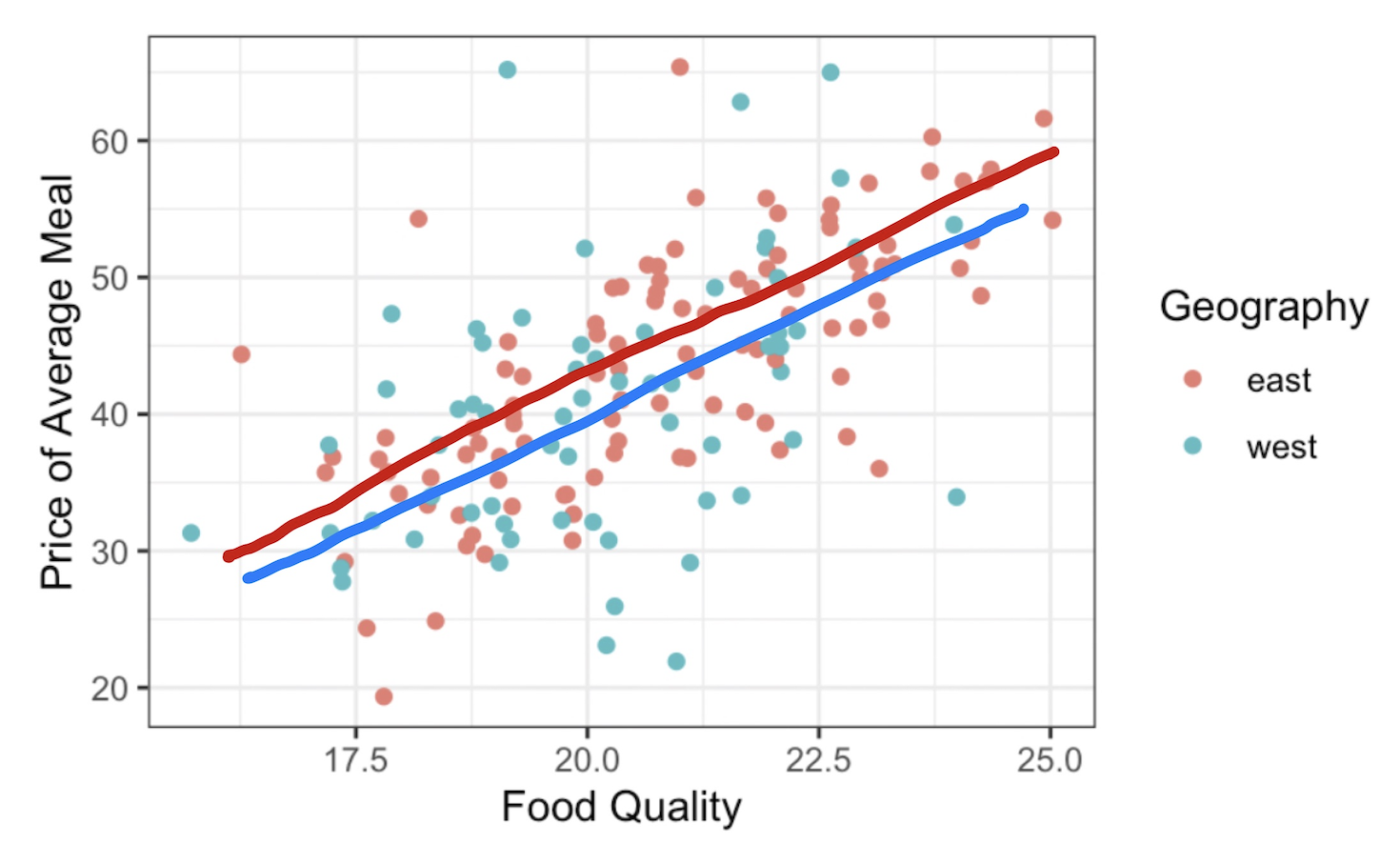
It looks like if you want a very tasty meal, you’ll have to pay for it. There is a moderately strong, positive, and linear relationship between food quality and price. This plot, however, has a third variable in it: geography. The restaurants from the east and west sides are fairly well mixed, but to my eye the points on the west side might be a tad bit lower on price than the points from the east side. I could numerically summarize the relationship between these three variables by hand-drawing two lines, one for each neighborhood.
For a more systematic approach for drawing lines through the center of scatter plots, we need to return to the method of least squares, which is done in R using lm(). In this linear model, we wish to explain the \(y\) variable as a function of two explanatory variables, food and geo, both found in the zagat data frame. We can express that relationship using the formula notation.
Call:
lm(formula = price ~ food + geo, data = zagat)
Coefficients:
(Intercept) food geowest
-15.970 2.875 -1.459 It worked . . . or did it? If we extend our reasoning from the last notes, we should write this model as
\[\widehat{price} = -15.97 + 2.87 \times food - 1.45 \times geo\]
What does it mean to put a categorical variable, geo, into a linear model? And how do three numbers translate into the two lines shown above?
Indicator variables
When working with linear models like the one above, the value of the explanatory variable, \(geowest\), is multiplied by a slope, -1.45. According to the Taxonomy of Data, arithmetic functions like multiplication are only defined for numerical variables. While that would seem to rule out categorical variables for use as explanatory variables, statisticians have come up with a clever work-around: the dummy variable.
- Dummy Variable
- A variable that is 1 if an observation takes a particular level of a categorical variable and 0 otherwise. A categorical variable with \(k\) levels can be encoded using \(k-1\) dummy variables.
The categorical variable geo can be converted into a dummy variable by shifting the question from “Which side of Manhattan are you on?” to “Are you on the west side of Manhattan?” This is a mutate step.
# A tibble: 168 × 4
food price geo geowest
<dbl> <dbl> <chr> <lgl>
1 22 43 west TRUE
2 20 32 west TRUE
3 21 34 west TRUE
4 20 41 west TRUE
5 24 54 west TRUE
6 22 52 west TRUE
7 22 34 west TRUE
8 20 34 east FALSE
9 22 39 east FALSE
10 21 44 east FALSE
# ℹ 158 more rowsThe new dummy variable geowest is a logical variable, so it has a dual representation as TRUE/FALSE as well as 1/0. Previously, this allowed us to do Boolean algebra. Here, it allows us to include a dummy variable in a linear model.
While you can create dummy variables by hand using mutate, in practice, you will not need to do this. That’s because they are created automatically whenever you put a categorical variable into lm(). Let’s revisit the linear model that we fit above with geowest in the place of geo.
\[\widehat{price} = -15.97 + 2.87 \times food - 1.45 \times geowest\]
To understand the geometry of this model, let’s focus on what the fitted values will be for any restaurant that is on the west side. For those restaurants, the geowest dummy variable will take a value of 1, so if we plug that in and rearrange,
\[\begin{eqnarray} \widehat{price} &= -15.97 + 2.87 \times food - 1.45 \times 1 \\ &= (-15.97 - 1.45) + 2.87 \times food \\ &= -17.42 + 2.87 \times food \end{eqnarray}\]
That is a familiar sight: that is an equation for a line.
Let’s repeat this process for the restaurants on the east side, where the geowest dummy variable will now take a value of 0.
\[\begin{eqnarray} \widehat{price} &= -15.97 + 2.87 \times food - 1.45 \times 0 \\ &= -15.97 + 2.87 \times food \end{eqnarray}\]
That is also the equation for a line.
If you look back and forth between these two equations, you’ll notice that they share the same slope and have different y-intercepts. Geometrically, this means that the output of lm() was describing the equation of two parallel lines:
- one where
geowestis 1 (for restaurants on the west side of town) - one where
geowestis 0 (for restaurants on the east side of town).
That means we can use the output of lm() to replace my hand-drawn lines with ones that arise from the method of least squares.
Reference levels
One question you still might have: Why did R include the dummy variable for the west side of town as opposed to the one for the east side?. The answer lies in the type of variable that geo is recorded as in the zagat dataframe. If you look closely at the initial output, you will see that geo is currently designated chr, which is short for character. geo is indeed a categorical variable with two levels: east and west.
Like in previous settings, R will determine the “order” of levels in a categorical variable registered as a character by way of the alphabet. This means that east will be tagged first and chosen as the reference level: the level of a categorical variable which does not have a dummy variable in the model. If you would like west to be the reference level, then you would need to reorder the levels using factor() inside of a mutate() so that west comes first. This would change the equation that results from then fitting a linear model with lm(), as you can see below!
Call:
lm(formula = price ~ food + geo, data = mutate(zagat, geo = factor(geo,
levels = c("west", "east"))))
Coefficients:
(Intercept) food geoeast
-17.430 2.875 1.459 Now our equation looks a little bit different!
\[\widehat{price} = -17.43 + 2.87 \times food + 1.46 \times geoeast\]
In general, if you include a categorical variable with \(k\) levels in a regression model, there will be \(k-1\) dummy variables (and thus, coefficients) associated with it in the model: one for each level of the variable except the reference level2. Knowing the reference level also helps us interpret dummy variables that are part of the regression equation; we will see this in a moment. For now, let’s move to our second scenario.
Three numerical
So far we’ve focused on price and food. But the Zagat reviewers scored a third numerical variable, too: decor. To understand how all three relate to one another, let’s start where we always do — by looking at the data.
# A tibble: 6 × 7
restaurant price food decor service geo y_hat
<chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl>
1 Daniella Ristorante 43 22 18 20 west 45.8
2 Tello's Ristorante 32 20 19 19 west 40.1
3 Biricchino 34 21 13 18 west 42.9
4 Bottino 41 20 20 17 west 40.1
5 Da Umberto 54 24 19 21 west 51.6
6 Le Madri 52 22 22 21 west 45.8As we did last week, we can model price on food ALONE and price on decor ALONE and get simple linear models. A natural first move is to look at these variables two at a time. Below are three scatter plots: price against food, price against decor, and food against decor.
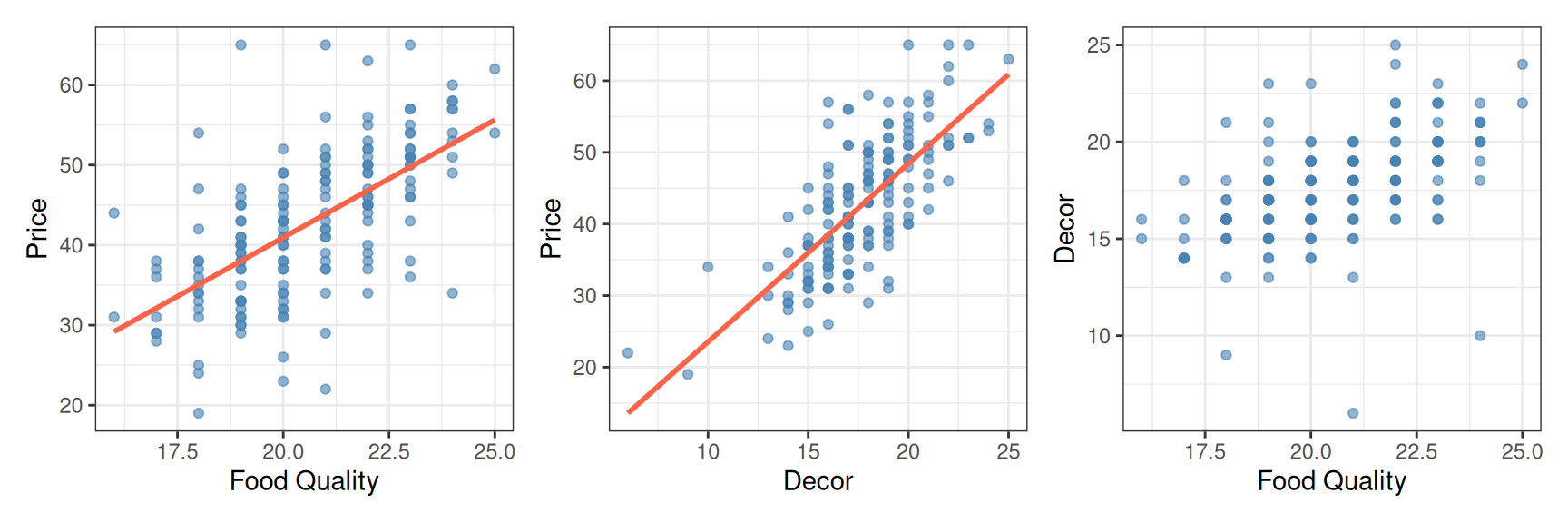
However, can we model price on food and decor AT THE SAME TIME? And will this give us a better model? It seems, knowing more information can only help us.
To visualize 3 numerical variables, we will use a 3D scatter plot.
You can think of the scatter plot like a cube you could hold in your hands, and each of the 2D scatter plots I made above is the shadow of the cube on its walls. Each data point gets a unique 3D location in space based on its (food, decor, price) coordinate.
Take a moment to explore this scatter plot. Can you find the name of the restaurant with very bad decor but pretty good food and a price to match? (It’s Gennaro.) What about the restaurant that has equally bad decor but has rock bottom prices that’s surprising given it’s food quality isn’t actually somewhat respectable? (It’s Lamarca.)
In 3D space, I can model price as a scaling of food plus a scaling of decor plus an intercept,
\[ \widehat{price} = b_0 + b_1 \times food+ b_2 \times decor \]
All my linear model does is pick values for \(b_{0}, b_{1}, b_{2}\).
Call:
lm(formula = price ~ food + decor, data = zagat)
Coefficients:
(Intercept) food decor
-24.500 1.646 1.882 We can write the corresponding equation of the model as
\[ \widehat{price} = -24.5 + 1.64 \times food + 1.88 \times decor \]
To understand the geometry of this model, in 3D space this is decribing what we call a plane. Think of it like a flat piece of paper cutting through the data.
If you inspect this plane carefully you’ll realize that the tilt of the plane is not quite the same in every dimension. The tilt in the decor dimension is just a little bit steeper than that in the food dimension, a geometric expression of the fact that the coefficient in front of decor, 1.88, is just a bit higher than the coefficient in front of food, 1.64.
Recall in a simple linear model, the residuals are the distance from each point to the line, let’s visualize the residuals of price vs food.
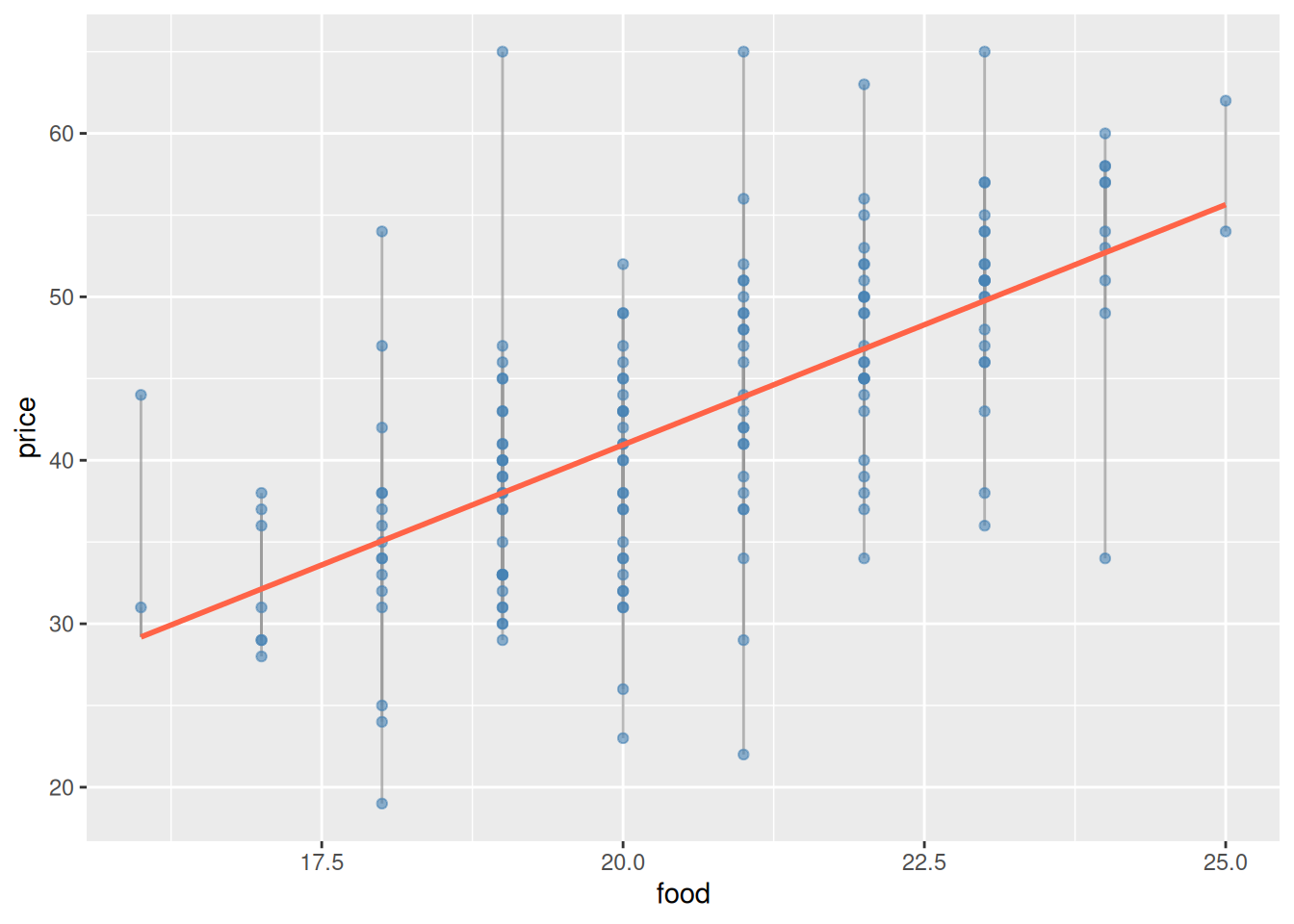
In 3D space, we also have residuals which are the distance from each point to the plane (this is still \(e_{i} = y_{i} -\hat{y}_{i}\), it’s just now in 3D space.)
Here is the thing. The 2D plot above is the best line, as a function of food alone, to have the lowest sum of squares residual. The plane is the best plane to have the lowest sum of squares residual. The plane WILL HAVE LOWER sum of squares residual every time, more information can only reduce the residuals.
Let’s look at two restaurants Rino Trattoria and Barbetta
# A tibble: 2 × 4
restaurant food decor price
<chr> <dbl> <dbl> <dbl>
1 Barbetta 20 23 52
2 Rino Trattoria 20 14 23They have the same food score, but different price and different decor. The food alone model cannot distinguish them on price, they are fit the same price value
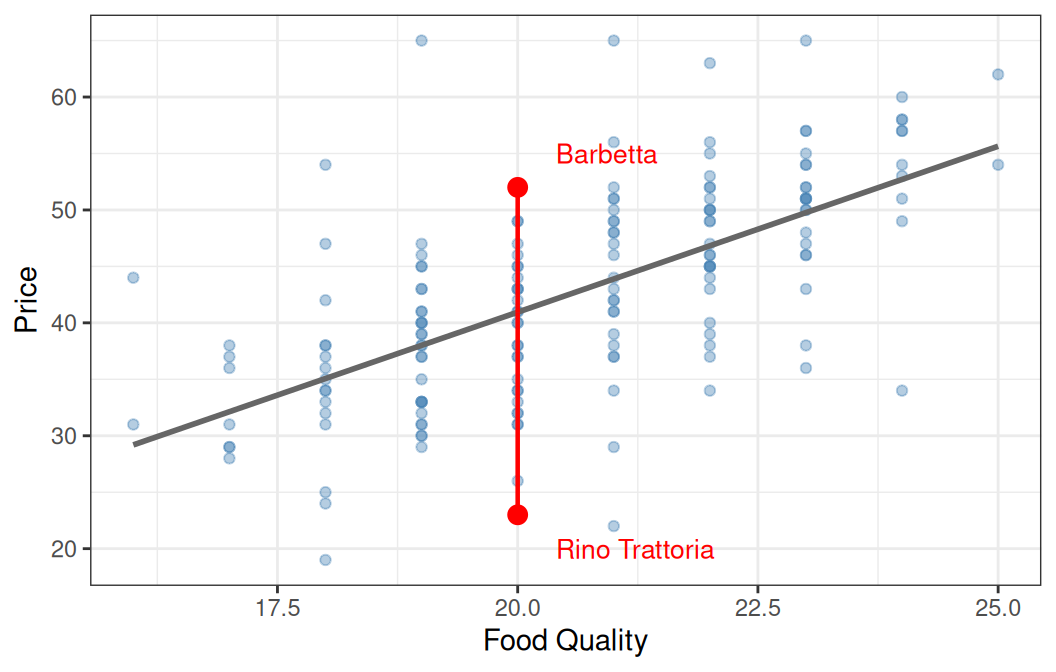
Yet these two restaurants have different decor scores, so the plane IS able to seperate them out and model different price values in 3D space for these two restaurants in a way the food alone model could not, hence why it can have lower residuals.
Finally, I want to point out that the coefficient on “food” in the price vs food model alone is NOT the same as the coefficient on the price vs food and decor, food may get a different coefficient than when it was modeled alone. On the food model alone we have
\[\widehat{price} = -17.83 + 2.94 × food \] in the food and decor model we have
\[\widehat{price} = -24.50 + 1.64 × food + 1.88 × decor \]
So when we ``add in’’ a new variable to our model, we should not think this variable will get its own coefficient, and food’s coefficient will stay the same as before. The addition of a new variable both changes the previous variable’s coefficient and gets a coefficient for itself.
Interpreting coefficients
When moving from simple linear regression, with one explanatory variable, to the multiple linear regression, with many, the interpretation of the coefficients becomes trickier but also more insightful.
Three numerical
Mathematically, the coefficient in front of \(food\), 1.64, can be interpreted a few different ways:
It is the difference that we would expect to see in the response variable, \(price\), when two Italian restaurants are separated by a food rating of one and they have the same decor rating.
Controlling for \(decor\), a one point increase in the food rating is associated with a $1.64 increase in the \(price\).
Similarly for interpreting \(decor\): controlling for the quality of the food, a one-point increase in \(decor\) is associated with a $1.88 increase in the \(price\).
Two numerical, one categorical
This conditional interpretation of the coefficients extends to the first setting we looked at, when one variable is numerical and the other is a dummy variable. Here is that model:
\[\widehat{price} = -15.97 + 2.87 \times food - 1.45 \times geowest\]
One might interpret \(food\) like this:
- For two restaurants both on the same side of Manhattan, a one point increase in food score is associated with a $2.87 increase in the price of a meal.
As for \(geowest\):
- For two restaurants with the exact same quality of food, the restaurant on the west side is expected to be $1.45 cheaper than the restaurant on the east side.
We make the comparison to the east side since this level is the reference level according to the linear model shown. This is a useful bit of insight - it gives a sense of what the premium is of being on the eastside.
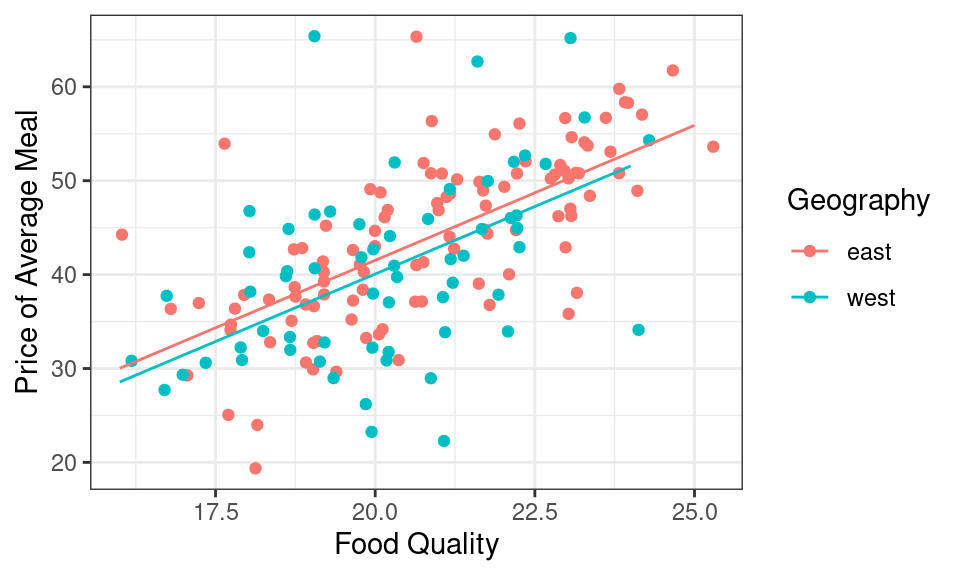
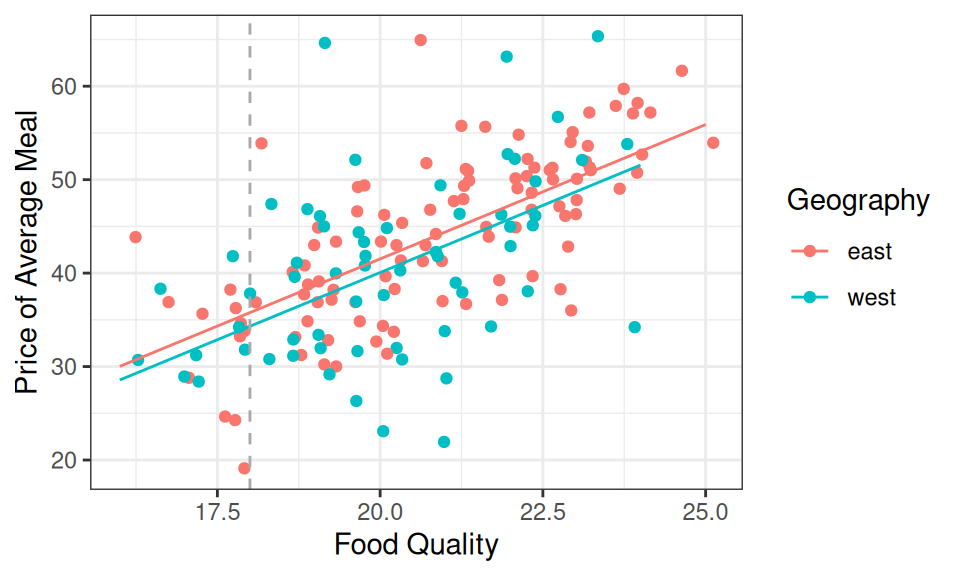
It is also visible in the geometry of the model. When we’re looking at restaurants with the same food quality, we’re looking at a vertical slice of the scatter plot. Here the vertical gray line is indicating restaurants where the food quality gets a score of 18. The difference in expected price of meals on the east side and west side is the vertical distance between the red line and the blue line, which is exactly 1.45. We could draw this vertical line anywhere on the graph and the distance between the red line and the blue will still be exactly 1.45.
What is “A Line”? More than you think! Polynomial Regression
Linear regression is a very powerful tool, and we need to expand a bit our idea of what “linear” means in this context. We probably all learned in high school that the equation for a line is
\[y = mx+b\]
and this is exactly what our linear model is fitting in a one variable model like
\[ \widehat{price} =2.94 × food -17.83 \]
But what is actually going on here in multiple linear regression is I have a data frame with some columns \(y, x_{1},x_{2}, \cdots, x_{N}\). I want to fit a value \(\hat{y}\) to explain the \(y\) column in terms of the \(x\) columns, and I can scale them in any way I want with \(b_{i}\) values, and a \(b_{0}\) intercept
\[\hat{y} = b_{0}+b_{1} \times x_{1}+\cdots+b_{N} \times x_{N}\]
“Linear” here means I am only allowed to scale my columns, once I pick my columns I am stuck with them.
But consider the following data example, which looks quite quadratic, not linear at all,
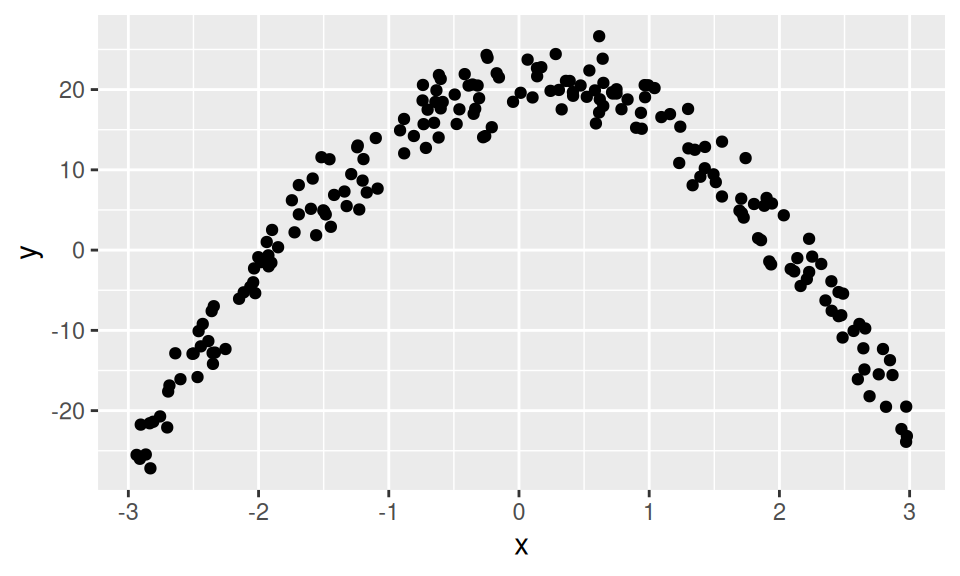
We can consider the data frame that made this and fit a linear model on \(x\) alone, but it will not be a great fit
x y
1 2.485291 -10.890085
2 -2.756030 -20.718033
3 -1.517095 11.572988
4 1.805018 5.742025
5 1.558852 6.678766
6 2.818649 -19.519574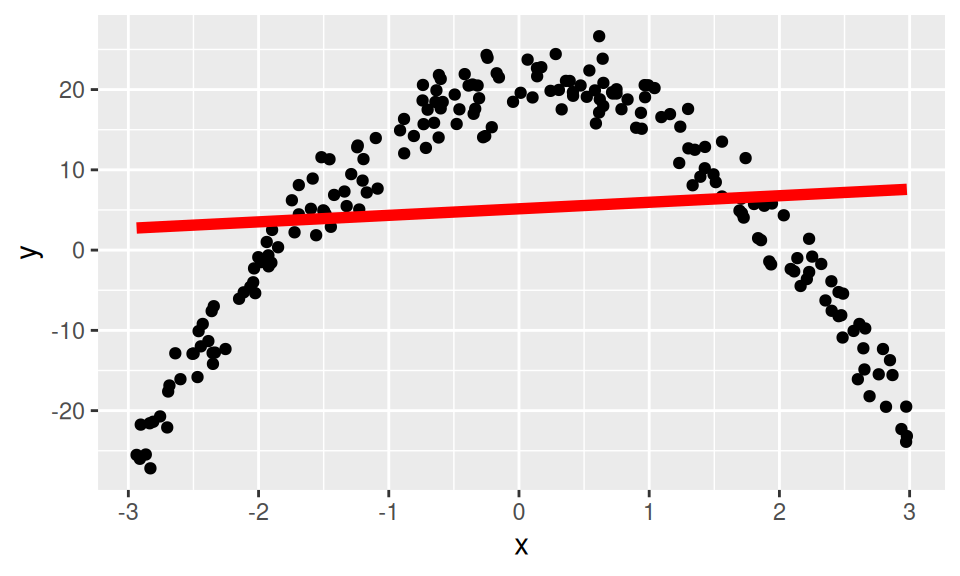
However, what if I mutate my data frame to make a new column called \(z\) which is x squared? Then I can fit a multiple linear regression
\[ \hat{y} = b_{0}+b_{1} \times x+b_{2} \times z\]
Yet \(z\) here is \(x^2\). There is no rule against this, multiple linear regression is just fitting scalings of my columns to the target data. So even though my new column happens to be x squared, that doesn’t really change anything we’ve discussed already. So really I am fitting
\[ \hat{y} = b_{0}+b_{1}\times x+b_{2}\times x^2\] which is the general form of a quadratic! So fitting a quadratic function IS linear regression! All I am doing is picking scalings of my data frame columns, and one of those columns so happens to be \(x^2\). Mind blown!

Here is the linear model using \(x\) alone, and the one which uses the \(x^2\) column.
y x x_sqr y_hat_1 y_hat_2
1 -10.890085 2.485291 6.176672 7.168945 -8.341884
2 -20.718033 -2.756030 7.595703 2.902237 -21.204082
3 11.572988 -1.517095 2.301576 3.910795 6.973304
4 5.742025 1.805018 3.258089 6.615167 5.717487
5 6.678766 1.558852 2.430018 6.414775 9.648973
6 -19.519574 2.818649 7.944784 7.440316 -16.944399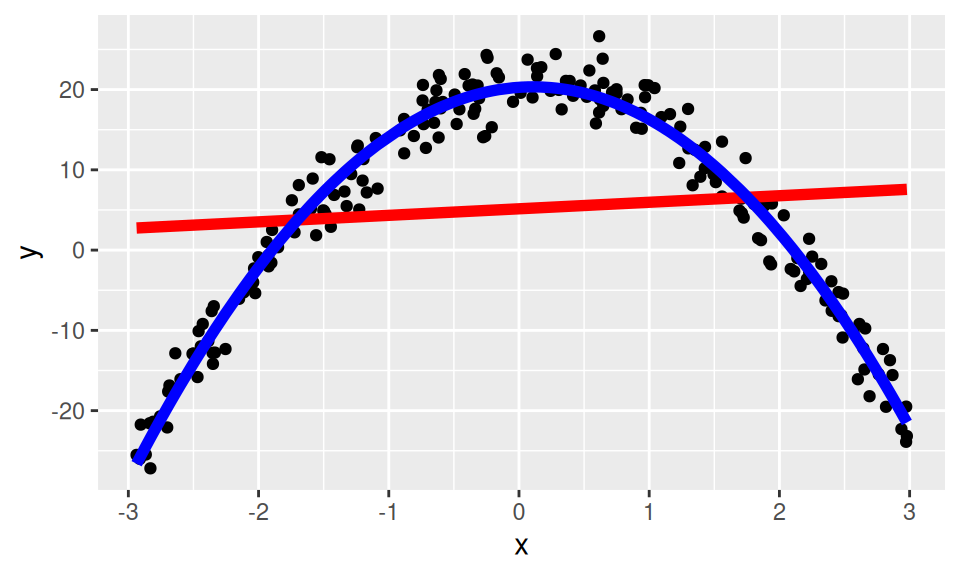
We can in general fit even higher order polynomials like cubic and get even more flexible fits
\[ \hat{y} = b_{0}+b_{1}\times x+b_{2}\times x^2+b_3 \times x^3\]
y x x_sqr x_cube y_hat_3
1 2.4174212 -1.4069480 1.9795027 -2.78505745 4.526963
2 4.5938025 -0.7672566 0.5886827 -0.45167068 4.604353
3 -5.6255616 0.4371202 0.1910741 0.08352232 -3.135866
4 12.7144888 2.4492467 5.9988096 14.69256484 12.479627
5 -0.9033124 -1.7899084 3.2037721 -5.73445869 1.289343
6 15.8849226 2.3903381 5.7137163 13.65771377 10.764833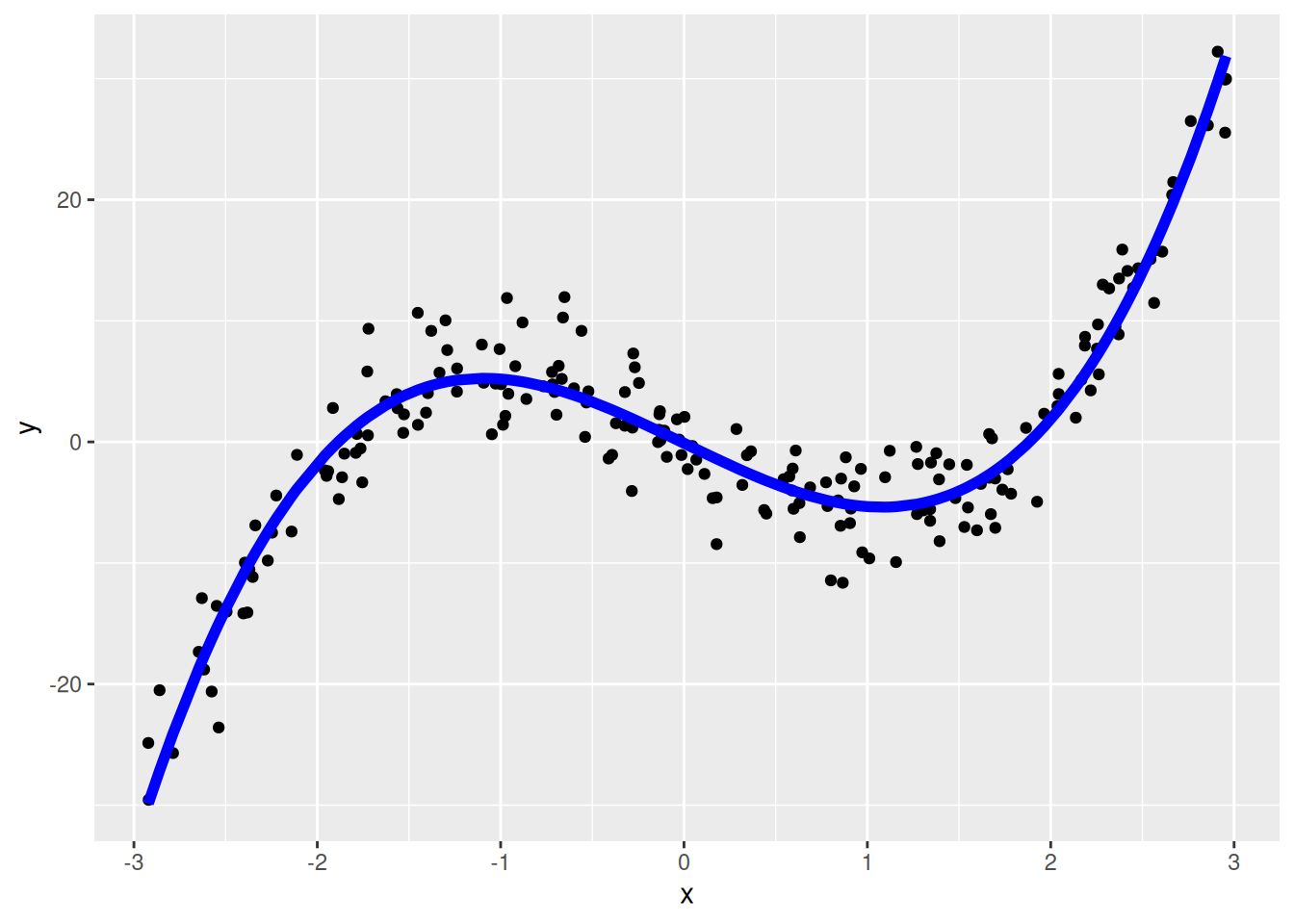
As long as I have columns in my data frame which are \(y,x, x^2\), and \(x^3\) as the values in those column, all I am doing is picking the coefficients (or scalings) of those columns. This is called polynomial regression, but really it is just a specific form of multiple linear regression where the column data happens to be polynomial values.
So you might think, I should always fit like 1 million degree polynomials to all my data and get perfect fits! But we have to be careful, more is not always better. We will discuss later in the course the idea of over fitting, when you fit the data too well. Adding more columns will always result in lower residuals, but that is not always the best course of action.
We are also starting to get into territory that is covered in the 4th unit of the course “prediction”, so we will stop here for now. But the take away is “linear” means a lot more than you think!
Summary
We began this unit on Summarizing Data with graphical and numerical summaries of just a single variable: histograms and bar charts, means and standard deviations. In the last set of notes we introduced our first bivariate numerical summaries: the correlation coefficient, and the linear model. In these notes, we introduced multiple linear regression, a method that can numerically describe the linear relationships between an unlimited number of variables. The types of variables that can be included in these models is similarly vast. Numerical variables can be included directly, generalizing the geometry of a line into a plane in a higher dimension. Categorical variables can be included using the trick of creating dummy variables: logical variables that take a value of 1 where a particular condition is true. We even saw we can fit seemingly “non-linear” models like quadratics, if we are smart about how we define the columns of our data frame. The interpretation of all of the coefficients that result from a multiple regression is challenging but rewarding: it allows us to answer questions about the relationship between two variables after controlling for the values of other variables.
If this felt like a deep dive into a multiple linear regression, don’t worry. Linear models are one of the most commonly used statistical tools, so we’ll be revisiting them throughout the course: investigating their use in making generalizations, causal claims, and predictions.