# A tibble: 1 × 3
xbar sx n
<dbl> <dbl> <int>
1 118. 81.5 30Confidence Intervals
STAT 20: Introduction to Probability and Statistics
Agenda
- Announcements
- Reading Questions: Confidence Intervals
- Break
- Lab 3: Part 1
- Appendix: more practice!
Announcements
- Quiz 1 grades should be matched now - apologies.
- Lab 3 deadline extended to Wednesday at 12:30pm. Part 2 shortened. See Ed for details.
- Portfolio 5 due Friday (Mon., Wed., Thu. worksheet)
- We will spend the majority of Thursday completing that day’s worksheet.
Reading Questions
- Please put your laptops under your desk and your phones away.
- Write your name, ID, and bubble in Version “A” on your answer sheet.
- You may work only with those at your table!
Is this a correct interpretation of a 90 percent confidence interval?
I am 90 percent confident that the sample mean is between the lower and upper bounds of my interval.
A: True
B: False
00:30
Is this a correct interpretation of a 90 percent confidence interval?
The probability that the population mean is between the lower and upper bounds of my interval is 0.90.
A: True
B: False
00:30
Which of the following is the most suitable definition of the standard error?
A: The standard deviation of the population
B: The standard deviation of a given sample from the population.
C: The standard deviation of a statistic upon hypothetical resampling.
00:30
True or False: A simple random sample of 400 units from a large population will be about 4 times more accurate as a simple random sample of 25.
A: True
B: False
00:40
Break
05:00
Lab 3: Part 1
05:00
Appendix - More practice!
Concept Questions
You embark on a mission to estimate a population mean using a simple random sample of \(n\) observations.
What sample size would you need to increase the precision of your estimate by approximately 3x compared to the original sample?
01:00
What is an approximate 95% confidence interval for the mean air time in flights using the normal curve?
01:00
An economist aims to estimate the average weekly cost of groceries per household in two cites: Oakland, CA (population ~400,000) and Fremont, CA (population ~200,000). Both of these populations of households are presumed to have a similar standard deviation of weekly grocery costs. The economist takes a simple random sample (without replacement) of 100 households from each city, records their costs, and computes a 95% confidence interval for the average weekly cost.
Approximately how much wider would Oakland’s confidence interval be than Fremont’s?
01:00
An economist aims to estimate the average weekly cost of groceries per household in two cites: Grimes, CA (population ~400) and Tranquility, CA (population ~800). Both of these populations of households are presumed to have a similar standard deviation of weekly grocery costs. The demographer takes a simple random sample (without replacement) of 100 households from each city, records their costs, and computes a 95% confidence interval for the average weekly cost.
Approximately how much wider would Tranquility’s confidence interval be than Grimes’s?
01:00
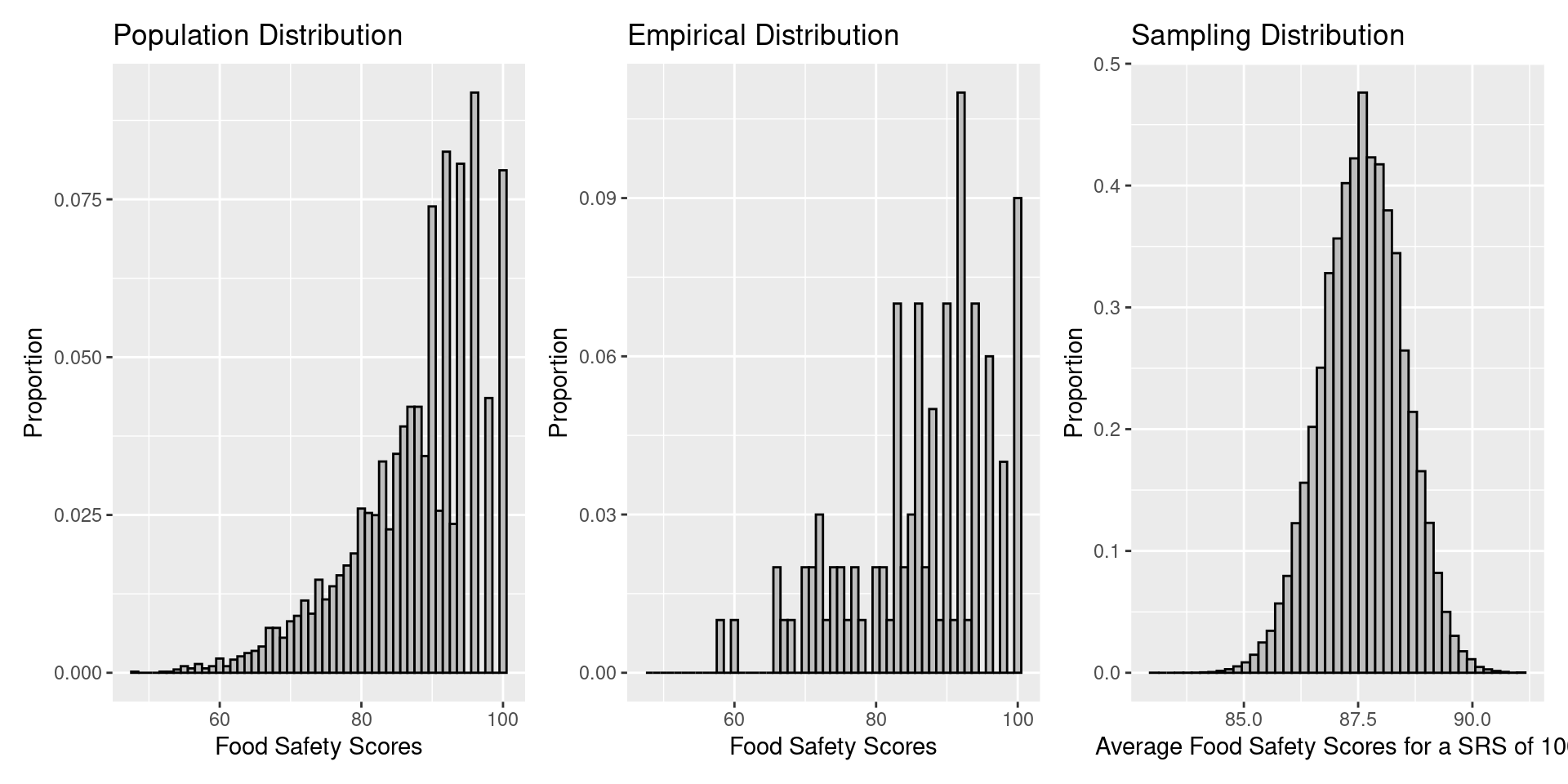
What will happen to the shape of the empirical distribution as we increase \(n\)?
01:00
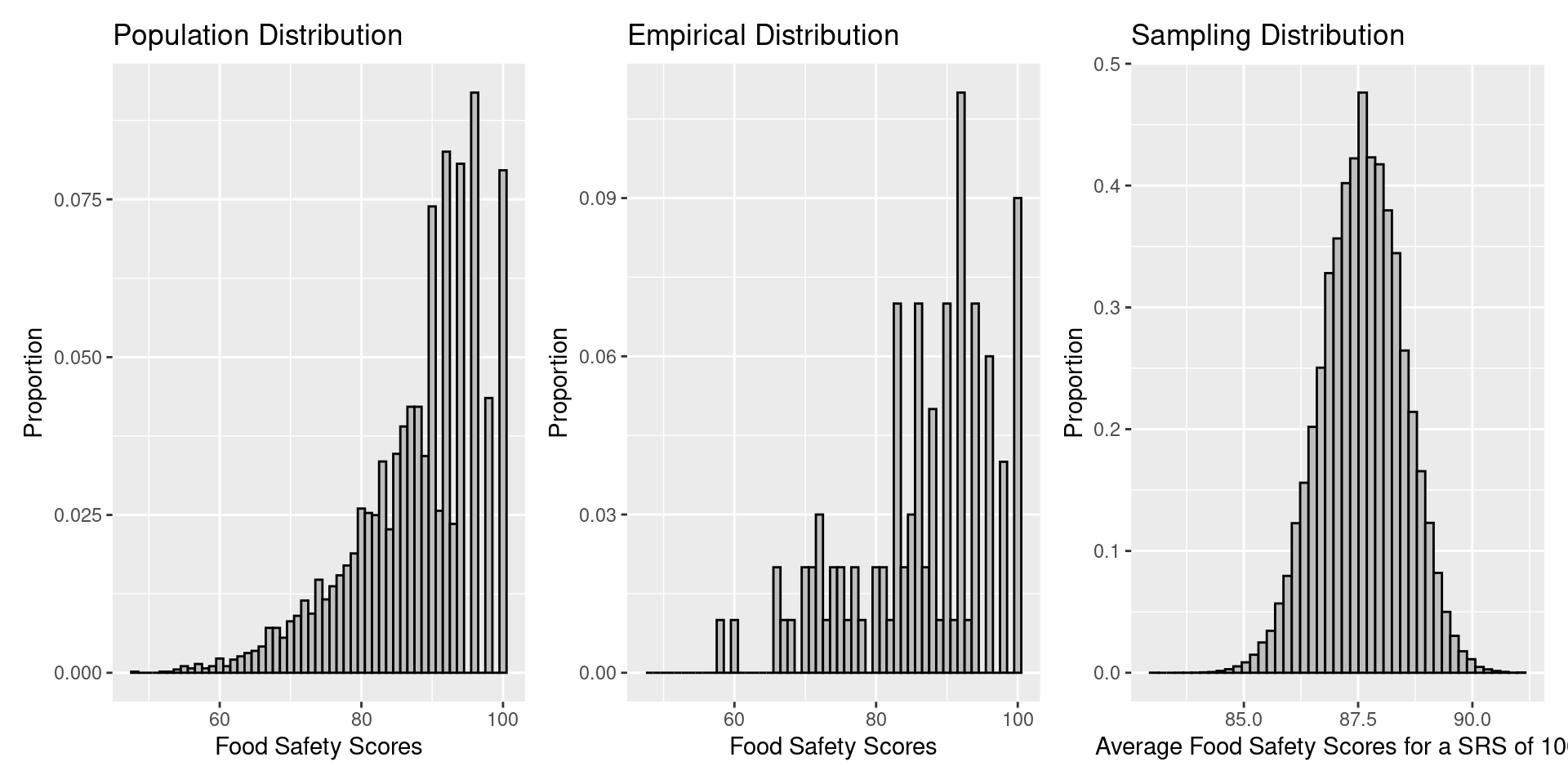
What will happen to the shape of the sampling distribution as we increase \(n\)?
01:00
